

- �� ҳ
- �λ�ע��
- WIC���㰸��
- �����ݽ��α�
- ��������
-
�ר��

- ���»
- ������ҵ���а�
- ���ܿƼ�������
- ˫��̸
- �������
-
����ع�
-
��������

 �ؼ��ʣ�
�˹�����
�ؼ��ʣ�
�˹�����
 2023-02-07 14:51:24
2023-02-07 14:51:24
 �ղ�
�ղ�

�ⲻ��AI��һ���������飬����AlphaGo����������ֵ�ʱ����ҵ�Ϳ�����һ��“AI�Ƿ��ȡ������”�Ŀֻ������ۣ��������ļ��꣬AI��û���������������һ����֪��ֱ��2022�꣬��Σ�AI�������Ժ��������������죻����Ѹ�ٻش�������Ҫʮ�����Ӳ��ܻش�Ĵ𰸣���Ѹ�ټ���������ܼ�Сʱ�����ռ������ϣ����ܴ���������������̾����“������”�Ļ滭��
�˹����ܹ�˾OpenAI���ⳡ�����еĽ��㣬����CEO Sam Altman˵��“ʮ��ǰ�Ĵ�ͳ�۵���Ϊ���˹��������Ȼ�Ӱ�������Ͷ���Ȼ������֪�Ͷ�����Ȼ��Ҳ����һ������������Թ��������ڿ��������������෴��˳����С�”ChatGPT�����ߣ��߸��������AI“��ռ”�����������֪���ⳡʼ�ڹ�ȵ�AI������£����ڵ��ż��IJ����ԣ�Ѹ�ٴ�����ͨ�˵����ChatGPT��2022��11�������������˹����ܹ�˾Open AI�Ĺ�ֵ�Ѿ��ߴ�290����Ԫ���Ƽ���ͷ���ٴ�С�AI��ҵ��˾Ħȭ���ơ���ͨ������AI�������У���IJ����ֺ���
ͬʱ��һϵ������Ҳ�����������ǵ���ǰ��
�� ����ʽAI�������Ƿ�����һ�������ƶ�������������ҵ�˳���
�� ���Ƿ���Ŀǰ����ҵ��ִ�����ĸı䣿
�� ����ʽAI��������������Щ��ҵģʽ�����ھ�
�� �й���ͷ���Ƽ���ҵ��ץס�ⳡ�µ�AI�˳�����
�� �߶�оƬ���ޣ��й����п��ܷ�չ�Լ���AI��ģ����
��Ѷ�Ƽ��Ի�ȫ��Ƽ����²�ҵר�ҡ��Ƽ�Ͷ���ˣ������ʱ���ʼ�ϻ�������ȫ�������������ȫ��Ƽ���ҵ�Ĺ۲켰����ʵ�������Իش������ѽ�����⡣��Щ���ⲻ���б��𰸣���������ϣ���ܴ���ҵ��Ȳ����ߵĶ�Ƕȹ۲��У�����ע“����ʽAI”�Ķ��ߣ�����һЩ������
01
AI���ɣ��ض�����Ƽ���ͷ������
Q1������ʽAIΪ������Ƽ���ͷ�Ĺ�ע��
����ȫ����һ��AI�滭��ChatGPT��Ӧ�õij��֣���Խ��Խ�����ͨ�û�����ʹ���˹����ܡ���������ѧ��Diego Comin����һ���������ǿ����ȡ�����������Ƚ��Ƽ����ٶȣ�����ȡ����ʹ���Ƚ��Ƽ�����ȡ�
���绥������������������뻥�������ٶȺܿ죬�������뻥������ʹ�ñ����͡��Ƽ�֮�������ƶ���ᷢչ������Ϊ�Ƽ��ܱ��㷺ʹ�ã��㷺������Ч�ʻ��ߴ����µ����������ֻ����������ʹ�ã�������Ч�ʻ��ߴ����µ��������С������OpenAI����ҵ�����۵��ȶ��������û������۵��ȶȣ����DZȽ��ټ��ģ����Ժ����˹����ܻ�����ȣ���˳�����£�ˮ�����ɵġ�
�ڶ�������ʽAI��Ӧ�ø�δ�������������ռ�������Ϊ����ʽAI���кܶ�ģʽ���µĿռ䣬Զû�дﵽ��ߵ㡣��Ȼ�����Ѿ�����̽����AIGC��ijЩʹ��ģʽ������Զ�����յ㡣�ر�����Ļ���������������Ż���վ�����Σ��ٵ����̣��ٵ�������Ƶ�ı���һֱ�ڵ�����չ��

ȫ������AIGC����������ҵ������Ƭ��Ȯ�����꡷������������AI����
��OpenAI�ļ��������Լ���Ƶ�ģʽ���ܹ����������Ӧ�ã�����˵����������ɹ��Ĵ�ҵ��˾�������������ռ䡣
֮ǰ���˹����ܴ�ҵ��˾�ʹ�ʼ�˶����˹�����ר�ң���������AIGC��Chat GPT�����ǿ����ᷢ�֣��ܶ��˹����ܴ�ҵ��˾�Ĵ�ʼ�˿��Բ��Ǽ���ר�ҡ�����������һ��idea��Ȼ����ȥ��ijλCTO����ʵ�֣�����CTOҲ�ȽϺ��ң���Ϊ������Щ��������������ʵ�ֲ����ѡ���ʱ���˹���������Ĵ�ҵ�ͻ��Ļ�Ծ��Ҳ������ν�����ڴ��¡���Ҳ�����������ԭ��֮һ�����ǻ���Ϊ�������“��”�ܽ��������ܹ��ճ�ʹ�����⣬����Ҫ��Ҳ��“��”���ܴ�ҵ������ʵ�����˴����ż����ø������ܹ����룬��ʹ�ÿƼ������ܹ��ӿ��г������ܹ�ʹ���µļ�ֵ���Գ������ⶼ���ر�������ġ�
Q2����ο������ƿƼ���ͷ����OpenAI�ĺ�����
����ȫ����һ����������֧������Open AI��˵�������Ǻܴ�ijɱ�����ˣ���ѡ������������Դ����������֧�����ڶ���δ���Ƽ��㡢�˹����ܡ������ݽ�����Ƚ�ϣ����������˹�����Ӧ���ǻ����ƽ��в�������Ҳ�������ṩ��OpenAI��Ҫ�����϶��ῼ��ѡ�������ƣ��ȸ��ơ�����ѷ�ơ����ƣ�������һ�䣬����˭��������һ�϶���ѡ�����Ը����ǿ�ҵģ�֮ǰ����Ͷ����Open AI��Ҳ�����˺�������Ը��
��������δ����չ����������������ѷ�ƵĿͻ�����Ƚϵ�һ����Ҫ��Ե��̿ͻ������ȸ��ڿ�����ҵ�ͻ������IJ����ã���Ȼ�ȸ��DeepMind���˹�����������о��dz����룬����ҵ����ز�����ɫ��������ҵ��������õģ����д�������ҵ�ͻ������������“������”��ʵ�ֺ������ϣ������ڴ�������ҵ�ͻ����ơ����OpenAI��˵Ҳ����Ҫ����Ʒ�ͷ������ÿͻ�����ʹ�ú����ǹؼ������д����û�ʹ�ã����������г�������˫Ӯ��
����Ҳ������OpenAI�����ĺ�����������OpenAI�Ŀ���API����ζ�Ŵ�ҵ��ֻҪ��Idea���Ϳ���ȥ����صĴ���������������˵��Ҳ�Ƿdz����ͻ�ơ��ع����ķ�չ���̣�����û��������뻥������ҵ����������ȫ�����绯������������������ҵ�ĽŲ������Ⲩ�˹������˳��У���Ҳ�ȹȸ��ƺ�����ѷ�ƶ���������������������ǰ�ߵIJ������������������У���������ʤ�������ƣ�ԭ��Ҳ��ֱ�ӣ�������Ӧ�õ��ϵĽ�ϸ��á�����ѷ���磬�ȸ�ļ���������ǿ��������������Ӧ�ý���϶�û����������ô��ɫ��OpenAI���Ͻ�����Ӧ�ý��DZ�Ȼ���ƣ��Ѹ�����˹�����������Ӧ�ý�ϣ��ø���������ܵ��˹����ܴ����ı������ø����д�����˲������У������г��Ż���ӻ�Ծ�����Դ�Ӧ���Ͻ����Ǽ������չ��
��һ������Ҳ�ܴ���������OpenAI��Ͷ��100����ԪͶ�ʣ�������ЩͶ����ҪOpenAI�ں��������ӯ�����ȸ����ֺ쳥��Ͷ�ʲ��û����ֹ�Ȩ�����OpenAIûǮ������������ռ��ԭ�йɷݣ�����Ҫ��ҵ���⸶������һ��˫Ӯ����ơ�
02
���ڵ�����ʽAI��
�е���������孺���ʱ��
Q3��������ʽAI������û�й۲쵽����������ҵģʽ��
����ȫ����Щ��ͷ�������е����껥��������������ʱ��ʱ�мҹ�˾����孺���������˵��“����”���й��ϰ��յ�������ʶ�������˰�����孺����߽����������硣��孺������Ż��Ͳ�һ�����Ż���ʵ����ҵӰ���孺����ߺܶࡣ�����е㴦���м�Σ������������Ļ���BBS�����ٻ�û���Ż��Σ������ζ�ſ����зdz������ģʽ���ڽ�����������֡�
���Ƕ�ԭ�����ܽᣬδ������ģʽӦ�ò��ǽ�“AIGC”���ǽ�“AIGS”����ΪC��Content�����о����Եģ���ʹAIGC��������ǿ��C�ĽǶ�����������ͬһ��ؼ��ʣ�������C�����Ƶģ��������������ǵĸ��Ի������������ļ�ֵ���ܹ��������һ�ַ���Service������Ҫʲô����ʲô���������˵õ��Ķ�������һ�������˵������ܱ����Ի������㣬��Ҳ�������������������ģ��ʱ���ĵ���������Ĺ�ģ������ָ����“�˹����ܵķ���”���������˵ķ�����Ϊ�˹��ǿ��Ը���“�����ģ���ĸ��Ի�”��
�߶˷�����ص���Ǹ��Ի���������“��”Ϊ“��”���ƣ����Խи߶ˣ�����Ҫ����ƣ�����Ҫ����һ���ĸ��Ӷȡ�����ChatGPT����Ļ�������ChatGPTд�����£��������㹻�ĸ��Ӷȣ��㹻���㡣
���磬2022��11��28�գ�26���ŦԼ������������Ъ��·�ƣ�Michelle Huang��������С����һ�ѡ������Լ�10����ռ��ϴ�����GPT-3��ѵ��������һ��С��Ъ����AI��������������֮��������ͼ�ŵ��������ϣ���Ϣһ�����������˲�С�Ĺ�ע��һ���ڵ����Ѿ�����5.1��Ρ��������ݷdz���������Ъ��·��������ξ�������һ�澵�ӣ������һ��˺ܶ��Լ�����û�иı�Ķ�����Ҳ���������˺ܶ��Ѿ���ʧ�ĵط��������������֪���������Ͻ�֪������������������“��”��ʲô���⡢ί�������ѣ�֪�����һ��˽��Լ�����δ������“���ַ���”���ܱ��һ�ַ����������ص���“��”�ø��˵�����ȥι�����������γɶ�����˵�������⡣

�û������ʱ����Ҫ����Զ���Dz�Ʒ���Ƿ�����Ҫ���ǹ�ģ���ķ�������Ϊ���˹����ܡ��л����ˣ���ҵ�Ĺ�ģ�����������ܹ��������Ի�����“��”�����������“��”����������ܹ����Ի��غ˿ͻ����������������Ի������������ṩ�߶˵ķ�������δ������ʽAI������ҵDZ����
Q4:����ʽAI��Ӧ��̽����Ҫ���Ǽ�����“�Ƽ�Ȧ”����רҵ��������Ա���Ƿ���ζ���ռ��ż���Ȼ�Ƚϸߣ�
����ȫ������Ϊ���Ǽ����ż������⡣�������й��̣�������Ա�������¼����Ͻ���20����ǰ����ȵ�һ����������Ӫ��ר��Jeffrey Moore�������“��Խ�ѹ����ۣ�Crossing the Chasm��”�������г��е��˷ֳ����࣬�����ȵ�һ���˽д����ߣ�Innovator��������һ�������ڲ����ߣ�Early Adapter���������ر�Ը��Ӧ���²�Ʒ��ʹ���²�Ʒ���������˾��Ǹ߿Ƽ���Ʒ�ĵ�һ���û���
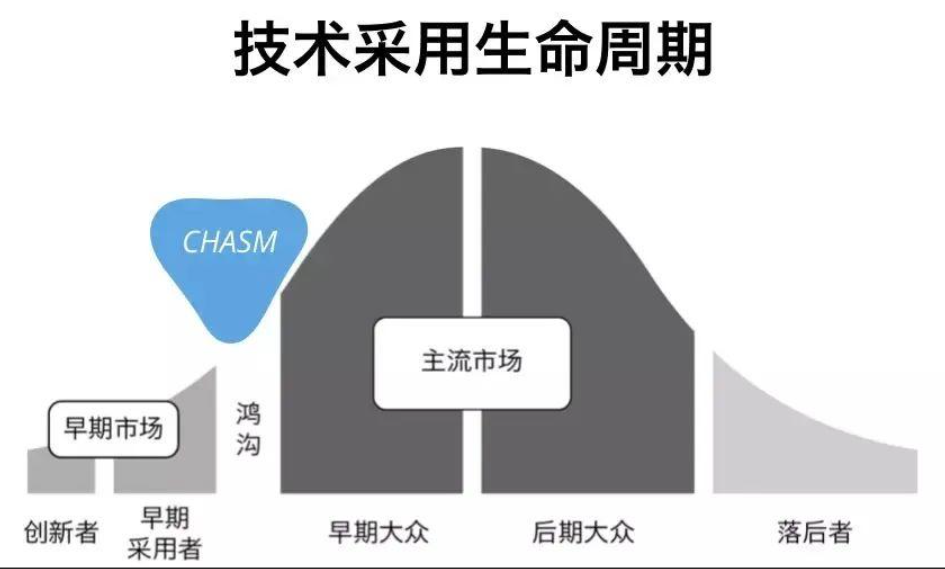
�������˶��������������ʹ�ã�������ʱ���Ʒ�����кܴ�覴ã��������Dz��Ầ��ʹ�ã����е����¹��ܡ��������������ܶ�߿Ƽ���Ʒһ��������һ�����ٵ��г�����������Ϊ�����û���
���Ǻ���������û��ֳ����������������������Ϻ��ȵ��û������������û���ǰ���������û�����Ϊϰ�ߺܲ�һ������������Ϊ����¹��ܾ�ȥʹ���㣬���ǻῴ�ҵ�ʹ�������Dz��ǵõ����㣬�Dz��Ǻ�����������������Ⱥ����“ ��”��Ӧ�ã���������Ҫ�ġ���Щ�߿Ƽ���˾���ڻ�õ�һ������������ʱ���������ʵ���ϻ�û���������Ⱥ���Ͽɣ���ʱ��������ʵ���Ͼͼ�������ҵ�IJ������⣬������ҵ�����Ʋ���
����˵�õ�CEO����������Early Adopter�����ڲ����ߣ�������һ���Ǵ����ߣ��������Ʋ��Ǵ����ߣ������������������ģ������������ڲ����ߣ���֪�������������ƾ���“��”�������������̣�����Ҳ֪���������������ǵ���û����֤�������Ժ������������Ա���ͨ���Ա���ѧϰeBayģʽ����ʵ�������з���eBayû�н���ij������⡣Ϊ�˽��������������֧��������ƽ̨��Ϊ�������м��ˣ��ȵ���ȷ���Ժ��ٸ����һģʽ�����˳������⡣
������Ͱͺ����ijɹ�������Ϊ���ļ�����ô���ȣ�������Ϊ���ڼ���Ӧ���н����Ӧ��ʹ�㣬���Ǻ����������������Ϊʲô����“����”����Ϊ����Ӵ��������������Ǽ�����Ա���������������Աֻ��ʹ�ü�������֪����ν�����⣬��������ļ�������ռ��ļ�����
ʲô����������£��ǷǼ�����ʹ���ߡ������Dz���ͨ������ȥ����Լ�������ʱ��ֻ����취�������ʱ��“��”�ܽ��������⣬���������ռ��ԣ����Ե�ʹ����˵��ΪOpenAI�ļ����������ر�Ĵ��ڻ�����������ĵ�һ����һ���Ǽ���ר�ң��������Ѿ����˴��ڻ�����ͷ����Ϊ�ܶ���������Ѿ����Ǽ���ר�ҡ�
����OpenAI��ChatGPT�Ѿ��Թ��ڽ��ż������dz��ͣ���ʱ�����ٲ�ʹ�ã��Ͳ�����Ϊ���ż������⣬������Ϊ��������ڲ�֪������ǰ�ؿƼ�����֪�������ڲ����ߣ���֪��Ҫʵʱȥ����ʹ�ã�ֻ��������“��”��Զ����Ϊ�Ƽ�����ͨ�����У�����������ʶ��Ϊ“�㲻��”������ʵ������ĸ㲻���������������⡢��̬���⡣
���������õ�Ťת�����гɹ����������������ڿ���Ӧ�ÿ�������ʹ�õ�ʵ�����ӣ����Ǽ�����ԱҲ����ת�Ƽ�������и��㷺��Ⱥ��������������������������Ϊ�Ѿ����Ǽ����ż���ԭ��
03
��Щר�Ҿ���ChatGPT“�Ƿ��м���ͻ��”��ʵ��¶����֪
Q5: AIGC��Chat GPT��AlphaFold������������һ��̸�ۣ������Ƿ���Ա���Ϊͬ����Ĵ�ҵ�����ܷ���“AI+”��
����ȫ������Ϊ���ԡ����Ƕ��ǽ�AI�����������������ȻAIҲ��N�������������������������ͼƬ������������������Ҳ�����������ġ������Ż�������������ʽAI�ļ����˳��£����и��ָ������¹��ܳ��֣���Щ���ܶ��ᱻ����һ�������ṩ������
�κε��µļ���ͻ���Ժ�Ҫ��һ��ģʽ������ʹ�ü���ͻ�Ƶ������ܹ������ӣ���ģʽ���µ�ǰ����Ҫ���“�������ױ��õ�”�����⣬������������ΪOpenAI�����ر�á���AlphaFold�Լ��������Ƶģ�̹������Ϊ����ȷʵ��Ƿȱ��
OpenAI��Ҫ����̸���������������ƣ���Google�������ƣ����ⷽ��������Deepmind�����������Ǹ���ģ�������Ҳ���Ƚ��Ŀ��гɹ�������������ͨ�û��㷺���õ�Ӧ�û���û�У���ʹ�����˵�����Χ���AlphaGo���������˲�û����DeepMind���ռ����������ף������Ⲩ����ʽAI���ȳ�������Ϊ���ľ��������˹����ܵ�ijЩ�������µ�ͻ�ơ�ʣ�µĹ�����������ù��ܱ��㷺ʹ�ã�����Ӧ�õĴ�Χ�ռ���
Q6����ר����ΪChatGPT��GPT-3û�м������£��ײ��������Transformer����ģ�ͣ���ο������ֹ۵㣿
����ȫ���������տ�ʼ����ʱ��Ҳ������Ϊ���������Ǽ������£�����ļ���������Tim Berners-Lee����ķ·����˹·����绥���������ߣ�������������������ʹ�á��Թ�����˵���Ἴ���������岻�ؼ���ʹ�á���Ȼ������µ�������������ģ�Ϊʲô������Ҫ����ʲô�Ǽ������£���Ϊ����ǿ������Ҫ�˵��ˣ���ʵ�����з��������Ҫ�����ڹ㷺ʹ�ã������õĴ��²������ܹ������ʾ����ô���Ŷ����ܹ����㷺ʹ�á�
�ܶ�õļ���������ר���Ѿ����ڣ�û��ʲô�¼�������ͻ�Ƶ����֮�£������ҳ�Ӧ��ʹ�㡢���Ӧ��ʹ���Ӷ��γ��ռ�������˵����˹����ʲô����ͻ�ƣ�﮵�ز����������ģ����������ܶ�ʱ���Ǽ��������ǿ��Է�����˹��Ӯ�������ϣ�����������Ȼ�ܹ����ֱ��˵ļ۸ܺõIJ�Ʒ���顣�������ܹ�����Ҳ��һ��“����”�����Բ���Ƭ������“ר��”���Ǽ�����“Ӧ�ô���”Ҳ�����ྭ��֪ʶ�Ļ��ۣ�“����ר����”�ľ�����۴�һ�������Ͻ�����Ҫ����������µ��ռ�����������һ���������г�������һ���ˣ����Dz�ҵ��ij�̬��
�����Ҫ����“�Dz�������м���ͻ��”����ô�Ƽ����µĹ��̶�Ӧ�ù������Ա����ɣ���ʵ����������Ա�������ó����Ƽ������ƹ㵽��ᡣ�����ó����µĶ����������µĶ���Ҫ�������ܣ�ҪEarly Adopter�����ڲ����ߣ�ȥ���֣���ʹ�õ��з���ʹ�����⣬Ȼ��ȥ������¼������֣�ԭ��ͻ����Innovator�������ߣ������£�����ͬ����﮵�س��֣���װ�������ŵ���100�����Ҫ����ʦ��������Ա�������ܵ��ţ������ܱ������ܣ���Щ�����ǿ�ѧ������ɵġ�
����Ϊ�Ƽ��ƹ㵽��ᣬ��������IJ��ǿ�ѧ�ң����ǿƼ���ҵ�ҡ�������˹�ˣ������Ǽ�����Ա����������Early Adopter����֪���綯�������������������㷺���ܡ����������۶ϵ���νר�ң�ǡǡ�DZ�¶���Լ�����֪���ԿƼ���������ƹ㵽���������֪�ġ�����Ϊֻ�п�ѧ�Ҿ����ˣ���ʵ��ԶԶ�����ģ�ֻ�п�ѧ�ҵĻ��������Ŀ��гɹ��������ڸ�У�����������ɡ�
��˹��˵����ʱ�����ͣ������жλ�˵�ĺܶԣ�Ӣ���и��ʽ�“Rocket Science”������û��“Rocket Scientist”����Ϊ�����ԭ����ͱ�������Space X�ijɹ����ǻ��ڿ�ѧ��ͻ�ƣ����ǻ��ڼ��������ƣ����ܵ��ŵ����ƣ������Щ�Ľ���“Rocket Engineer”�������ƶ�������ռ��IJ��ǻ����ѧ�Ҷ��ǻ������ʦ������ǿƼ���ҵ�����壬�����������Ͻ���OpenAI�DZ��ĿƼ���ҵ������δ������ԭ���������ܹ�����������ռ���ǡǡӦ�ø�лOpenAI��ʹ�ÿ�ѧ�ҵ��о��ɹ�û�аѣ��ܹ��������ɡ�

Q7: ���۶�˵“������Transformer����Щ����ģ����δ����ͨ�ü������ͺ�����������ӡˢ�����綯��������˵������
����ȫ���ؼ�������ô����Transformer������������ͨ�����ܣ���Ϊ���������ܵģ�����һ��ͨ��ѵ��ģ�͡�
���ȣ���ǰ��ÿһ��������˹�����Ҫ�Ƚ���ѵ��ģ�ͣ�Ȼ������ѵ��������ѵ��ģ�������ѵģ��������˹����ܵļ���ר�Ҳ���������������ѵ��ģ����ֻҪ�ò�ͬ������ѵ���ͻ��Ϊ��ͬ��“ר��”����������Ȼ��ͨ�ã���˼������Χ��ѵ����������Χ��ר�ң�������ѵ����������������ר�ҡ�ѵ���������壬���Ͳ�����Χ�塣���������ż������ˣ�ѵ��������ͬһ��������Transformer�ļ�ֵ���������һ���̶��Ͻ������ż�.
��Σ���ͨ��ѵ��������ͨ�����ݵ�ѵ�����ṩ�����ڵ����������ǽ����GPT-3����ÿ��һ�ζԻ�������ȫ��������ѵ����ѵ����ɺ��κ�������Ѿ����˴𰸣�������������������һ�������ݼ��������ر��˲���ĵط���
����ĺ��ļ�ֵ���������Ƕ�֪ʶ�Ļ㼯�������ʹ��С����������“��ľʽ����”������ÿ�����¾���һ���µĻ�ľ�����ϻ�ľ��ε�����һ���γ��µļ������Ǿ��ǿ�֪ʶ�Ļ㼯�������ʹ��С�����ԭ���и��о��Ǿ����鱨��Competitive Intelligence��������һ��˵���ǣ�����֪ʶ�Ĵ����������֪ʶ��������ij���˵�ͷ����û�����Գ��������ǵ�����PC֮������֪ʶ�����Ի��ӿ��ˡ���ȥ������“д��”�ķ�ʽ������֪ʶ���Ի����ٶ��DZȽ����ģ����һ�������ͼ��ݱ����������鷢�������ǻ�����ʱ��֮����������������¼������֪ʶ���Ի����ٶȴ��ӿ졣
OpenAI�����Զ�ȥ����һ�����֣��ⲻ���µ����ɣ����Ƕ�����������֪ʶ������������Ϊֹ�˹�������û�д������ģ��˹�����û�д�����֪ʶ���˹�����ֻ�Ǹ��õİѾ�֪ʶ�ۺϺͳ��ֳ�����Ҳ�������û������֪ʶ����GPT-3����“ɵ��”����Ϊʲô��ÿ���˶�����������Χ��Ϊʲô��Ӯ����ʯ����Ϊ�������е�Χ�徭��ȫ���㼯������
Q8: δ��AI��ô����ռ��ĺ�����ģ�ͻ��Ǵ����ݣ�
����ȫ����Ȼ����Ҫ�߱���������Ҫ���ǣ�ȫ�����֪�����ǿ��������������ķ��������ڴ��ڶԻ���������֪Խ��Խ�ḻ��Ӧ��Խ��Խ�ռ���������Խ��Խ�ࡣ����������OpenAI���������������ߴ����˹����ܿ�����“���淨”�����˶���������ʹ���˹����ܣ�������ʱ���ڻ��ǹ涨����——��Ȼ�����ʴ�δ�����ܻ���ָ������ѡ������
�����ҵ������ǣ�ģ�ͺ���Ҫ�������ݺ���Ҫ�����Ǹ���Ҫ����ȫ���ʹ�á����Ժʹ��¡��ż����ͺ����˶�����˴��µ��ʸ����ͻ�����䵽�ʱ䣬���൱����Զ�д����ˣ��ܶ�Ƽ�������Ӧ�õij��ֲ�������Ŀ�ĵķ���������ij����ijһ���“���һ��”��������һ����뵽��������쿪��ʢ�ۣ��ͻ��и�������˼�Ľ�����֡�
04
�߶�оƬ�����ƣ�
�ҹ���η�չ�Լ���“AI��ģ��”��
Q9����ο��������“��ģ��”�Ŀ�Դ��Ϊʲô���ǻ�û��������ģ�ͣ��ҹ���û�б�Ҫȥ��չ�Լ���“��ģ��”��
����ȫ���й��б�Ҫ����һ���Լ��Ĵ�ģ�͡�һ�������Ļ�����Ӣ�IJ�ͬ���������Ļ������й��Լ��������и��õı��֡���ν�����ģ�ͱ����Ѷ�Ҳ����ʵ�������ѧ�����ķ�������֪����ô��ʵ����������������ȥʵ�������⡣
���ڴ�ģ�͵����Ч������һ��������Ϊ����Ͷ���ԭ���Ƽ���ijɱ��Ǿ�ģ��������Ͷ���ߺ���ҵ�ҵ��������й��Լ��Ĵ�ģ��������Ҳ��Ҫ��������Ϊ�����й�û����������ԭ������Ϊ�������⣬Ҳ������Ϊģ�ͱ��������⣬����Ϊ���ǵĿ��������⣬�ܶ�ʱ��Ը��ţ���������ǡǡ�Dz��ܽ����ĺ���ԭ��
����OpenAI���и���Ц�����и����������⣬���ǰ�����¶�������Ѵ���¶���������������ͻ�Խ��Խ�á��������˵�����Ͳ����죬���˹����ܾͲ���ѧ�����ԡ��ͺ�����ѧϰ���ԣ���˵���ܶණ����������ȥ��������������˵���ˡ��˹����������ص����������ѧϰ�����ƣ��ر��ط�����OpenAI��ʵ���˲������ѹ�������ṩ����ң��ô�������ֳ��ԣ���ʹ���ڶ��˺ܶ���������������������У������ϵس����������й���ҵ��ͷ����ҵ�����Զ���������ð�ʵ���ҳɹ����ų���������á�һ������ѿ��ţ������ɱ�����ߣ���ҪΪ���ڵ����ʹ����������ʵ������������Ҳ���ڰ����ĥ��Ʒ�������ԣ���һ���ڰ��ķ�ʽ�������Ʋ�Ʒ��
���⣬������ν��IT��ͳ��OpenAI�������ǻ�������IT�Ŀ��Ŵ�ͳ��һֱ�������������ˣ���ҵ��վ�����Ǹ�һ��“������ʹ�ð�”���й����ֿ��ŵĴ�ͳ�������˵�����ܶ࣬��ҵ��û����ҵվ�����Ǹ�һ�������������Լ��о����ͱ��˵ĺ����ԱȽ���������������ǵ��ռ��Բ�ܶࡣ
OpenAI�Ļ��ȣ���ʵҲ���й���ͷ���Ƽ���ҵ�����˾�������ʵ���ǵ�ͷ����ҵҲ���ڸ㣬���Ǵ�Ҷ�ϲ�����ں�̨�㣬�����֮����ҫһ���������ϰ��������룬“�������”�ĸ߿Ƽ�������ܿ���������ֻ�д�Ҷ��㷺������ĺڿƼ���ĥ�����ܽ��������ҵ��ģʽ������OpenAI�Ĵ�ҵ�������Ѿ��ɹ�ģ�ˣ����Ǻܶ���ҵ�ر�ϣ��������״̬�������ҵ�ƽ̨��ҵ���ҵ�ƽ̨�ͷḻ����Ծ������˵�����ǵ�ͷ���Ƽ���ҵ�Ѿ������˵�һ��������˵�����˰������ܲ��ܾ�����������Ҿ������Ƿdz���Ҫ�ġ�
Q10��������Դ��OpenAI�Ŀ�Դ���ԺͰ��Ŀ�Դ��������dz�˵ƻ������̬���Ƿ�յģ����ǻ���ƻ����ƽ̨��Ҳ���������ָ�����Ӧ�á�
����ȫ��“��Դ”��“Ӧ�ù��ܵ����ɵ���”�������£�������ʵ���ں��IJ��ǿ�Դ�����ǹ��ܵ����ɵ��á����ǰ������ڴ�����OpenAI��ʹ�ã���ʵ���ǻ��ڿ�Դ���������Ϊ�ChatGPTƽ̨�ǻ��ڿ�Դ�ij���������������л��кܶ�knowhow�����Ժܶ˾�����������GPT��δ�������Ӫ��knowhow������
���ϸ���˵ ChatGPTƽ̨�Ͳ��ǿ�Դ�ģ����ⲻ������ȥ����ʹ�ã����൱�����Ƕ�֪��ƻ��ƽ̨����Դ�����������д���ʹ�ã�ֻҪ��������ǰ�ἴ�ɡ���һ��ǰ�����û������ڶ���ǰ�����ܹ��������ŵ��ù��ܣ����û������㹻���ƽ̨��ȥ���ù��ܣ�ȥʵ��һ��Ӧ�ã������㹻����û��ܹ����档
�����Ŀ����Ծ��㹻��������������ǿ�����ǿ����ԣ�����һ���ǵ�ǿ����Դ�������������������Ľ����ŵ���������Ŀ������ܹ�ȥ���ã���ƽ̨�Ĺ��ܱ������Ӧ�õ�һ���֣�ƽ̨�Ĺ���ʵ��ʵ�ʼ�ֵ���Ǿ��и�������Ŀ����������Ľ���Ĺ���ֲ�뵽�Լ���Ӧ���У�����ͳ����ˡ�
Q11���й��ĸ߶�оƬ���ޣ�����չAI��ģ����Ҫ�������֧�֣����Ƿ�Ҳ�������й�AI��ҵ��δ����չ��
����ȫ�����ڹ���������������һ���������й�оƬ�����һ��������������Ҫ��оƬ���������������������оƬ��ҵ�ں��Ѿ���20��֮�ã��ڼ��и��ֳ��ԣ����Ч���������룬�ټ�����������ó��Ħ���ļӾ磬�Է���ȡ�������ֶΡ���ȥ20��ĸ��ִ���Ŭ����û��ͻ���������й�оƬ�����ӵ����ƣ�������ʵ��
�����һ�����ԭ����ʲô��Ϊʲô���պ����ˣ���Ϊ���պ���������ˣ����ǽ�������ˡ�������оƬ��ҵ����֮�����������������������ձ���ҵ��������ASML(��˹��)�Լ�������ŷ����ҵ���롣����漰���Ƽ����µ�ľͰ���ۡ����Ƕ�֪����ͳ��ľͰ������Ϊ��ҵ�����ж̰壬�����ֽ���ľͰ���ۣ���ҵҪ��һ�����壬Ȼ�����������������������оƬ��ҵ��̬����ʮ����ſ�ʼ����������
�κ��µ���̬�ڽ����ʼ��û�г��壬���Ƕ̰壬�������ڴ�����̬֮����Ҫ�������������չ�������Ƕ̰嵫������˺����IJ�ҵ��չ�����и����̰����ݱ�ɳ��壬����ľͰ�ij��������������Ķ�����ƴ�������ġ�
������ǶȾͿ���֪��Ϊʲô�����й���оƬ��ͻ���ر����ѣ���Ϊ�������ҵ���ҵ�ں����гɳ���Ϊʲô����Ҫ�������ģ����ڳ��ں���������֪��Ը��˴����������һ�¡����ڵ����������������ȥ�ö̰��������˺�����չ��һ���棬�����Ͻ��������£�����������⣬�����ܻ�Ƚ�������Ϊ����Ҳ����Ҫ������ҵ��̬��Э��������ɣ����ֻ������һ��������Э��������ϣ��Ǵ���ͻ�ƾͻ��쳣���ѡ�
�������ģ�оƬ��ҵ��û�ж�������ʷ������оƬ��ҵ������ֳ����µĸ�������һ�ֿƼ�����û�и��ϣ�����һ�ֿƼ�������������Ҫ��ע�������Խ�������ܳ���������������Ȼ��������Ҳ���þ�ɥ����Ϊ����ܶ࣬����һ����������˹����ܡ��˹�����������ص���ʲô��������̬�����Ӷ����Ǹ�����ȥ�ǵ�оƬ�����ʱ����Ҫ��ѭĦ�����ɣ�������Ǿ���̸��“Ħ������ʧЧ��”���������ҵ�Ƴ���SOC��ϵͳ��оƬ����һ��оƬ��������N��CPU��N��GPU������GPU�����Խ��칹���㣬��ͨ�ü��㵥Ԫ��ר�м��㵥Ԫ������ר�м��㵥Ԫ�����ڲ��컯��
�����ֻ���ר��Ϊͼ��������һ�����㵥Ԫ��ר��Ϊ��Ƶ��������һ�����㵥Ԫ�����Ծ��γ�һͨ�ô����ר�õ���ϣ�����ṹ����������Ч�ʣ��������ܺģ�����������Ҫ��ߵļ����ٶȣ�����ʵ�ָ��õ�Ч������Ҳ��ζ������оƬ�����ϵ�Ҫ����Խ��ͣ����ǵ�оƬ���ž����ۺ����ţ������ҹ��ڵ�оƬ�ϵ������Dz��ǾͿ����ֲ���
��һ���棬�й����������ģ��ܹ��ø���Ĵ�����Ӧ�û�����ȥ���˹����ܽ�ϣ��������ϵͳоƬ���㷨�̻����ص㡣�����Ͻ�Ϊij����ҵר��ѵ����ҵ���ݣ��õ������Ż����㷨���ٰ��㷨�̻���Ӳ����оƬ�У��ù̻���оƬȥ������ʵ�����˹������������ţ�����͵����Ӿ����Զ���ʻоƬ����˹��Ϊʲô�����з���ʻоƬ��ԭ�������Զ���ʻ������������������ģ�����ô����Զ���ʻ������ȥѵ����Ȼ��õ�����Զ���ʻ�Ż��������ݣ��������Ч�ġ�
�й�������������ϵͳоƬ�칹����ʱ�����ܹ�����ӵ�����ݵĻ�������Ԥѵ����Ȼ����ӵ��оƬ����ܹ��Ĺ�˾��Ⱥ���������оƬ������ˮƽδ������ã���оƬѵ����ģ������õģ��������SOCоƬ��ϵͳ�����������ǿ�ģ���Ȼ�л���ʤ����
һ����оƬ��ҵ��һ�����˹�������ҵ��һ����Ӧ���ܹ������������ݵ�Ӧ����ҵ���ܹ��и��������ѵ��ģ�����̻���Ӳ���У����й��ͻ�ת����Ϊ���ơ����Զ���ʻ��ҵ���Կ�����������Զ���ʻ��ҵ��������ҵ��һ�����Զ���ʻ������ҵ��������������·�������ݡ���һ����оƬ��˾����������Ҫ���˹����ܹ�˾���Զ���ʻ�з���˾����Ӳ����ͨ������ѵ��Ӳ������ϵͳ��ʹ���Զ���ʻ������������������ܹ�ʵ���Զ���ʻ�����㹻���㡣�Զ���ʻ���˹����ܵ�ʾ���Է���������ģʽӦ�ó����ڸ�����ҵ�����У��κ����㹻���ݵ���ҵ����Ӧ���Դ�Ϊ��ʽ�����й����п���ת����Ϊ���ơ�
����Ϊ������й�����������ҵ����Ӧ����ҵ�IJ���������������ϵͳоƬ����ʤ������������7���ף�����48����ͬ�����ã��ƿ���оƬ�����֣�ͬʱ�ܹ�ʹ��Ӧ���ռ�����ϵͳоƬ������Ӧ�õ���Ƚ�ϣ��γɻ��������Ż����㷨���̻���оƬ��ҵ�Ľ�������У�������һ��оƬ�����ĺ��ġ�
��Դ����Ѷ�Ƽ�
 �������ܲ�ҵ����� ���ϴ����ˣ���
���Ƕ�̬ | ���ǻ�չ���ܷ�ó�ᣬע����������ȫ�»�����
�������ǡ���������쿪��Խ���Ժ���Զ����
�������������������������
�����ʻعˡ����ǿ����һ��AI�������й������������������ؼ�����������Ӧ��
�����ʻعˡ���Ӣ�� ������AIGC ����������ʱ������δ��
�����ʻعˡ��ܺ�t ��ӵ����ģ�� ��������������
�����ʻعˡ������� ���˹��������Ի��ӿ�
�����ʻعˡ���Ԫ�� ���˹����ܸ����������������ٽ��й��������ܻ�����ɫ����չ
�����ʻعˡ����˺� ���������������� ̽����������������ҵʵ��
�������ܲ�ҵ����� ���ϴ����ˣ���
���Ƕ�̬ | ���ǻ�չ���ܷ�ó�ᣬע����������ȫ�»�����
�������ǡ���������쿪��Խ���Ժ���Զ����
�������������������������
�����ʻعˡ����ǿ����һ��AI�������й������������������ؼ�����������Ӧ��
�����ʻعˡ���Ӣ�� ������AIGC ����������ʱ������δ��
�����ʻعˡ��ܺ�t ��ӵ����ģ�� ��������������
�����ʻعˡ������� ���˹��������Ի��ӿ�
�����ʻعˡ���Ԫ�� ���˹����ܸ����������������ٽ��й��������ܻ�����ɫ����չ
�����ʻعˡ����˺� ���������������� ̽����������������ҵʵ��




�������ܲ�ҵ������
��ICP��17008349��-3![]() �������� 12010302002098�� �ٷ�����
�������� 12010302002098�� �ٷ�����